项目介绍
Kubernetes是Google团队发起的开源项目,它的目标是管理跨多个主机的容器,提供基本的部署,维护以及运用伸缩,主要实现语言为Go语言。kubernetes是:
- 易学:轻量级,简单,容易理解
- 便携:支持公有云,私有云,混合云,以及多种云平台
- 可拓展:模块化,可插拔,支持钩子,可任意组合
- 自修复:自动重调度,自动重启,自动复制 Kubernetes构建于Google数十年经验,一半来源于生产规模的经验。结合了社区最佳的想法和实践。 在分布式系统中,部署、调试、伸缩一直是最为重要的也是最为基础的功能。Kubernetes就是希望解决这一系列问题的。
Kubernetes能够运行在任何地方!
虽然Kubernets是最初为GCE定制的, 但是在后续版本中陆续增加了其他云平台的支持,以及本地中的心的支持
快速上手
目前,Kubernetes支持在多种环境下的安装, 包括本地主机,云服务。然后最快速体验Kubernetes方式显然是通过本地Docker的方式启动相关进程。
下图展示了在单节点使用Docker快速部署一套Kubernetes的拓扑。
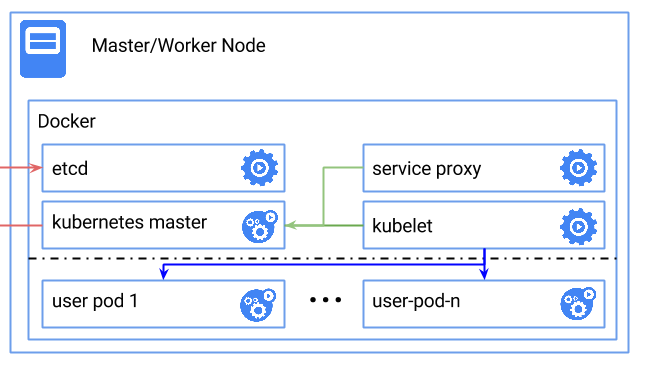 Kubernetes依赖Etcd服务来维护所有节点的状态
Kubernetes依赖Etcd服务来维护所有节点的状态
启动Etcd服务
1
docker run --net=host -d gcr.io/google_containers/etcd:2.0.9 /usr/local/bin/etcd --addr=127.0.0.1:4001 --bind-addr=0.0.0.0:4001 --data-dir=/var/etcd/data
启动主结点
启动 kubelet。
1
docker run --net=host -d -v /var/run/docker.sock:/var/run/docker.sock gcr.io/google_containers/hyperkube:v0.17.0 /hyperkube kubelet --api_servers=http://localhost:8080 --v=2 --address=0.0.0.0 --enable_server --hostname_override=127.0.0.1 --config=/etc/kubernetes/manifests
启动服务代理
1
2
docker run -d --net=host --privileged gcr.io/google_containers/hyperkube:v0.17.0 /hyperkube proxy --master=http://127.0.0.1:8080 --v=2
测试状态
在本地访问 8080 端口,可以获取到如下的结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
$ curl 127.0.0.1:8080
{
"paths": [
"/api",
"/api/v1beta1",
"/api/v1beta2",
"/api/v1beta3",
"/healthz",
"/healthz/ping",
"/logs/",
"/metrics",
"/static/",
"/swagger-ui/",
"/swaggerapi/",
"/validate",
"/version"
]
}
查看服务
所有服务启动后,查看本地实际运行的 Docker 容器,有如下几个。
1
2
3
4
5
6
7
8
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ee054db2516c gcr.io/google_containers/hyperkube:v0.17.0 "/hyperkube schedule 2 days ago Up 1 days k8s_scheduler.509f29c9_k8s-master-127.0.0.1_default_9941e5170b4365bd4aa91f122ba0c061_e97037f5
3b0f28de07a2 gcr.io/google_containers/hyperkube:v0.17.0 "/hyperkube apiserve 2 days ago Up 1 days k8s_apiserver.245e44fa_k8s-master-127.0.0.1_default_9941e5170b4365bd4aa91f122ba0c061_6ab5c23d
2eaa44ecdd8e gcr.io/google_containers/hyperkube:v0.17.0 "/hyperkube controll 2 days ago Up 1 days k8s_controller-manager.33f83d43_k8s-master-127.0.0.1_default_9941e5170b4365bd4aa91f122ba0c061_1a60106f
30aa7163cbef gcr.io/google_containers/hyperkube:v0.17.0 "/hyperkube proxy -- 2 days ago Up 1 days jolly_davinci
a2f282976d91 gcr.io/google_containers/pause:0.8.0 "/pause" 2 days ago Up 2 days k8s_POD.e4cc795_k8s-master-127.0.0.1_default_9941e5170b4365bd4aa91f122ba0c061_e8085b1f
c060c52acc36 gcr.io/google_containers/hyperkube:v0.17.0 "/hyperkube kubelet 2 days ago Up 1 days serene_nobel
cc3cd263c581 gcr.io/google_containers/etcd:2.0.9 "/usr/local/bin/etcd 2 days ago Up 1 days happy_turing
这些服务大概分为三类:主节点服务、工作节点服务和其它服务。
主节点服务
- apiserver 是整个系统的对外接口,提供 RESTful 方式供客户端和其它组件调用;
- scheduler 负责对资源进行调度,分配某个 pod 到某个节点上;
- controller-manager 负责管理控制器,包括 endpoint-controller(刷新服务和 pod 的关联信息)和 replication-controller(维护某个 pod 的复制为配置的数值)。
工作节点服务
- kubelet 是工作节点执行操作的 agent,负责具体的容器生命周期管理,根据从数据库中获取的信息来管理容器,并上报 pod 运行状态等;
- proxy 为 pod 上的服务提供访问的代理。
其它服务
- Etcd 是所有状态的存储数据库;
- gcr.io/google_containers/pause:0.8.0 是 Kubernetes 启动后自动 pull 下来的测试镜像。
基本概念
- 节点(Node):一个节点是一个运行 Kubernetes 中的主机。
- 容器组(Pod):一个 Pod 对应于由若干容器组成的一个容器组,同个组内的容器共享一个存储卷(volume)。
- 容器组生命周期(pos-states):包含所有容器状态集合,包括容器组状态类型,容器组生命周期,事件,重启策略,以及 replication controllers。
- Replication Controllers:主要负责指定数量的 pod 在同一时间一起运行。
- 服务(services):一个 Kubernetes 服务是容器组逻辑的高级抽象,同时也对外提供访问容器组的策略。
- 卷(volumes):一个卷就是一个目录,容器对其有访问权限。
- 标签(labels):标签是用来连接一组对象的,比如容器组。标签可以被用来组织和选择子对象。
- 接口权限(accessing_the_api):端口,IP 地址和代理的防火墙规则。
- web 界面(ux):用户可以通过 web 界面操作 Kubernetes。
- 命令行操作(cli):kubecfg命令。
节点
在 Kubernetes 中,节点是实际工作的点,节点可以是虚拟机或者物理机器,依赖于一个集群环境。每个节点都有一些必要的服务以运行容器组,并且它们都可以通过主节点来管理。必要服务包括 Docker,kubelet 和代理服务。
容器状态
容器状态用来描述节点的当前状态。现在,其中包含三个信息:
主机IP
主机 IP 需要云平台来查询,Kubernetes 把它作为状态的一部分来保存。如果 Kubernetes 没有运行在云平台上,节点 ID 就是必需的。IP 地址可以变化,并且可以包含多种类型的 IP 地址,如公共 IP,私有 IP,动态 IP,ipv6 等等。
节点周期
通常来说节点有 Pending,Running,Terminated 三个周期,如果 Kubernetes 发现了一个节点并且其可用,那么 Kubernetes 就把它标记为 Pending。然后在某个时刻,Kubernetes 将会标记其为 Running。节点的结束周期称为 Terminated。一个已经 Terminated 的节点不会接受和调度任何请求,并且已经在其上运行的容器组也会删除。
节点状态
节点的状态主要是用来描述处于 Running 的节点。当前可用的有 NodeReachable 和 NodeReady。以后可能会增加其他状态。NodeReachable 表示集群可达。NodeReady 表示 kubelet 返回 Status Ok 并且 HTTP 状态检查健康。
节点管理
节点并非 Kubernetes 创建,而是由云平台创建,或者就是物理机器、虚拟机。在 Kubernetes 中,节点仅仅是一条记录,节点创建之后,Kubernetes 会检查其是否可用。在 Kubernetes 中,节点用如下结构保存:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
{
"id": "10.1.2.3",
"kind": "Minion",
"apiVersion": "v1beta1",
"resources": {
"capacity": {
"cpu": 1000,
"memory": 1073741824
},
},
"labels": {
"name": "my-first-k8s-node",
},
}
Kubernetes 校验节点可用依赖于 ID。在当前的版本中,有两个接口可以用来管理节点:节点控制和 Kube 管理。
节点控制
在 Kubernetes 主节点中,节点控制器是用来管理节点的组件。主要包含:
- 集群范围内节点同步
- 单节点生命周期管理
节点控制有一个同步轮寻,主要监听所有云平台的虚拟实例,会根据节点状态创建和删除。可以通过 –node_sync_period标志来控制该轮寻。如果一个实例已经创建,节点控制将会为其创建一个结构。同样的,如果一个节点被删除,节点控制也会删除该结构。在 Kubernetes 启动时可用通过 –machines标记来显示指定节点。同样可以使用 kubectl 来一条一条的添加节点,两者是相同的。通过设置 –sync_nodes=false标记来禁止集群之间的节点同步,你也可以使用 api/kubectl 命令行来增删节点。
容器组
在 Kubernetes 中,使用的最小单位是容器组,容器组是创建,调度,管理的最小单位。 一个容器组使用相同的 Docker 容器并共享卷(挂载点)。一个容器组是一个特定运用的打包集合,包含一个或多个容器。
和运行的容器类似,一个容器组被认为只有很短的运行周期。容器组被调度到一组节点运行,直到容器的生命周期结束或者其被删除。如果节点死掉,运行在其上的容器组将会被删除而不是重新调度。(也许在将来的版本中会添加容器组的移动)。
容器组设计的初衷
资源共享和通信
容器组主要是为了数据共享和它们之间的通信。
在一个容器组中,容器都使用相同的网络地址和端口,可以通过本地网络来相互通信。每个容器组都有独立的 IP,可用通过网络来和其他物理主机或者容器通信。
容器组有一组存储卷(挂载点),主要是为了让容器在重启之后可以不丢失数据。
容器组管理
容器组是一个运用管理和部署的高层次抽象,同时也是一组容器的接口。容器组是部署、水平放缩的最小单位。
容器组的使用
容器组可以通过组合来构建复杂的运用,其本来的意义包含:
- 内容管理,文件和数据加载以及本地缓存管理等。
- 日志和检查点备份,压缩,快照等。
- 监听数据变化,跟踪日志,日志和监控代理,消息发布等。
- 代理,网桥
- 控制器,管理,配置以及更新
替代方案
为什么不在一个单一的容器里运行多个程序?
- 1.透明化。为了使容器组中的容器保持一致的基础设施和服务,比如进程管理和资源监控。这样设计是为了用户的便利性。
- 2.解偶软件之间的依赖。每个容器都可能重新构建和发布,Kubernetes 必须支持热发布和热更新(将来)。
- 3.方便使用。用户不必运行独立的程序管理,也不用担心每个运用程序的退出状态。
- 4.高效。考虑到基础设施有更多的职责,容器必须要轻量化。
容器组的生命状态
包括若干状态值:pending、running、succeeded、failed。
pending
容器组已经被节点接受,但有一个或多个容器还没有运行起来。这将包含某些节点正在下载镜像的时间,这种情形会依赖于网络情况。
running
容器组已经被调度到节点,并且所有的容器都已经启动。至少有一个容器处于运行状态(或者处于重启状态)。
succeeded
所有的容器都正常退出。
failed
容器组中所有容器都意外中断了。
容器组生命周期
通常来说,如果容器组被创建了就不会自动销毁,除非被某种行为触发,而触发此种情况可能是人为,或者复制控制器所为。唯一例外的是容器组由 succeeded 状态成功退出,或者在一定时间内重试多次依然失败。
如果某个节点死掉或者不能连接,那么节点控制器将会标记其上的容器组的状态为 failed。
举例如下。
- 容器组状态 running,有 1 容器,容器正常退出
记录完成事件
如果重启策略为:- 始终:重启容器,容器组保持 running
- 失败时:容器组变为 succeeded
- 从不:容器组变为 succeeded
- 容器组状态 running,有1容器,容器异常退出
记录失败事件
如果重启策略为:- 始终:重启容器,容器组保持 running
- 失败时:重启容器,容器组保持 running
- 从不:容器组变为 failed
- 容器组状态 running,有2容器,有1容器异常退出
记录失败事件
如果重启策略为:- 始终:重启容器,容器组保持 running
- 失败时:重启容器,容器组保持 running
- 从不:容器组保持 running
当有2容器退出
记录失败事件
如果重启策略为:- 始终:重启容器,容器组保持 running
- 失败时:重启容器,容器组保持 running
- 从不:容器组变为 failed
- 容器组状态 running,容器内存不足
标记容器错误中断
记录内存不足事件
如果重启策略为:- 始终:重启容器,容器组保持 running
- 失败时:重启容器,容器组保持 running
- 从不:记录错误事件,容器组变为 failed
- 容器组状态 running,一块磁盘死掉
杀死所有容器
记录事件
容器组变为 failed
如果容器组运行在一个控制器下,容器组将会在其他地方重新创建 - 容器组状态 running,对应的节点段溢出
节点控制器等到超时
节点控制器标记容器组 failed
如果容器组运行在一个控制器下,容器组将会在其他地方重新创建
基本架构
运行原理
下面这张图完整展示了 Kubernetes 的运行原理。
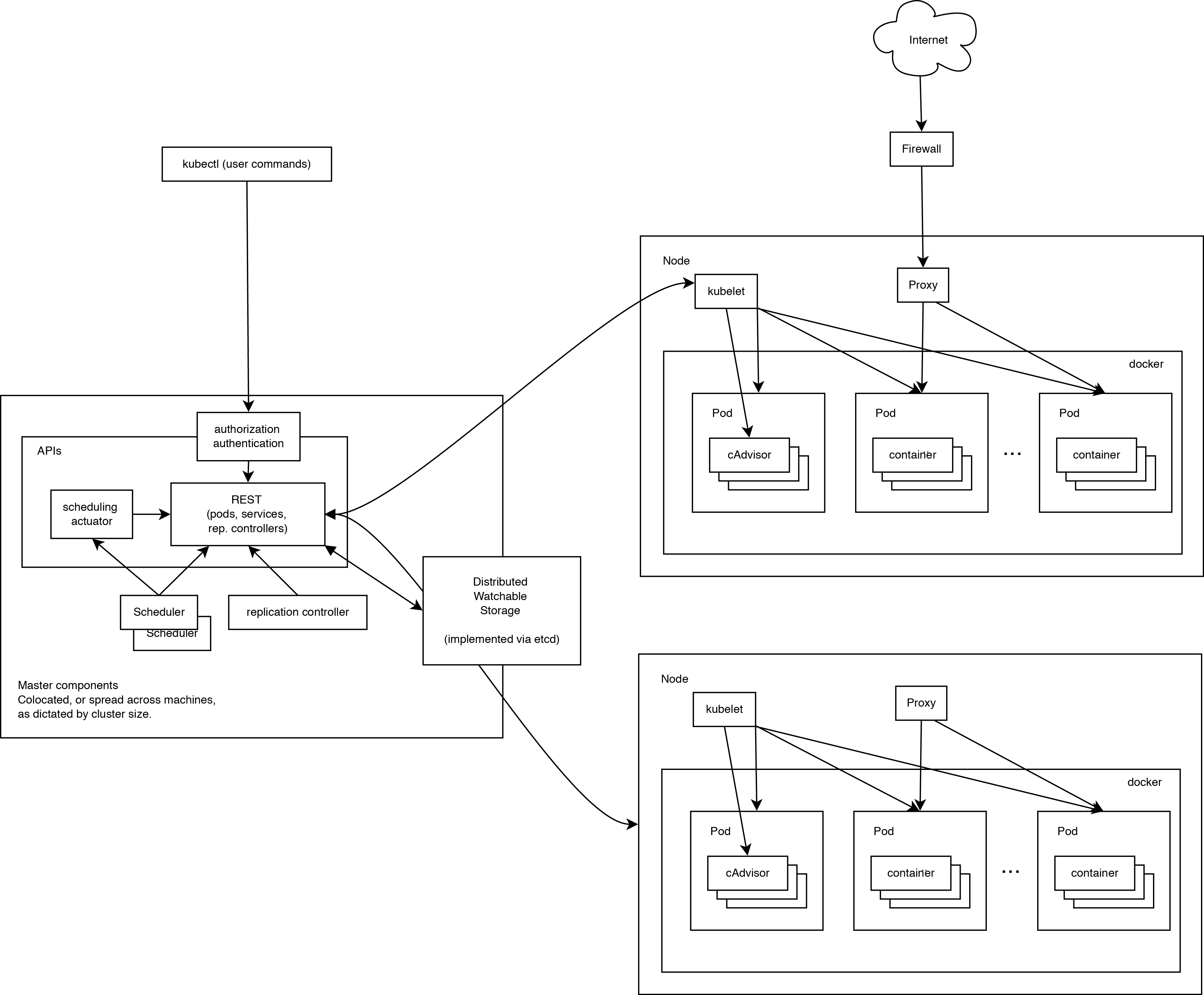 可见,Kubernetes 首先是一套分布式系统,由多个节点组成,节点分为两类:一类是属于管理平面的主节点/控制节点(Master Node);一类是属于运行平面的工作节点(Worker Node)。
可见,Kubernetes 首先是一套分布式系统,由多个节点组成,节点分为两类:一类是属于管理平面的主节点/控制节点(Master Node);一类是属于运行平面的工作节点(Worker Node)。
显然,复杂的工作肯定都交给控制节点去做了,工作节点负责提供稳定的操作接口和能力抽象即可。
从这张图上,我们没有能发现 Kubernetes 中对于控制平面的分布式实现,但是由于数据后端自身就是一套分布式的数据库 Etcd,因此可以很容易扩展到分布式实现。
控制平面
主节点服务
主节点上需要提供如下的管理服务:
- apiserver 是整个系统的对外接口,提供一套 RESTful 的 Kubernetes API,供客户端和其它组件调用;
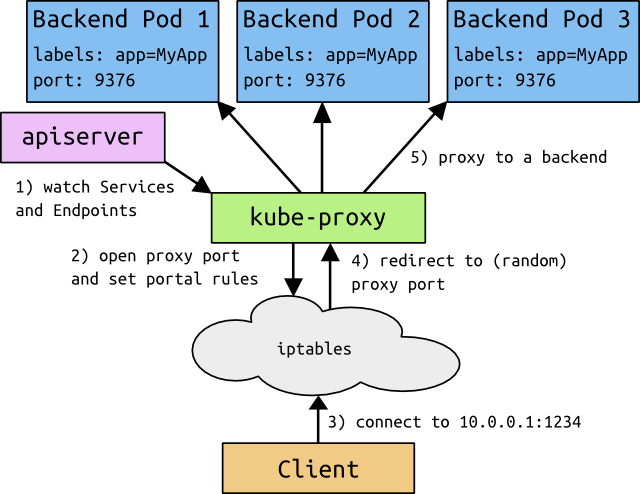
- scheduler 负责对资源进行调度,分配某个 pod 到某个节点上。是 pluggable 的,意味着很容易选择其它实现方式;
- controller-manager 负责管理控制器,包括 endpoint-controller(刷新服务和 pod 的关联信息)和 replication-controller(维护某个 pod 的复制为配置的数值)。
Etcd
这里 Etcd 即作为数据后端,又作为消息中间件。
通过 Etcd 来存储所有的主节点上的状态信息,很容易实现主节点的分布式扩展。
组件可以自动的去侦测 Etcd 中的数值变化来获得通知,并且获得更新后的数据来执行相应的操作。
工作节点
- kubelet 是工作节点执行操作的 agent,负责具体的容器生命周期管理,根据从数据库中获取的信息来管理容器,并上报 pod 运行状态等;
- kube-proxy 是一个简单的网络访问代理,同时也是一个 Load Balancer。它负责将访问到某个服务的请求具体分配给工作节点上的 Pod(同一类标签)。